


Section: New Results
People detection in monocular video sequences
Participants : Etienne Corvee, François Brémond, Silviu-Tudor Serban, Vasanth Bathrinaryanan.
A video understanding system analyzes human activity by detecting people in video sequences and tracking their displacement and movement throughout the sequences. The better the detection quality, the higher the semantic level of the information is. People activty can differ greatly from one application to another e.g. the presence of a person in one zone can simply be detected from a moving pixel region in a manually specified zone whereas detecting people fighting in a subway requires more complex information. For people activity to be recognized, one needs to detect people accurately in videos and at real time frame rate. Current state of the art algorithms provide generic people detection solutions but with limited accuracy. In the people monitoring domain, although cameras remain mostly fixed, many issues occur in images. For example, outdoor scenes display strong varying lighting conditions (e.g. sunny/cloudy illumination, important shadows), public spaces can be often crowded (e.g. subways, malls) and images can be obtained with a low resolution and can be highly compressed. Hence, detecting and tracking objects in such complex environment remains a delicate task to perform. In addition, detecting people has to face one major difficulty which is caused by occlusion where important information is hidden. When people overlap onto the image plane, their foreground pixels cannot be separated using a standard thresholding operation from a background reference frame. Therefore vision algorithms need to use information held by the underlying pixels and located at specific locations such as body parts.
We have extended our work by implementing and testing a novel people, head and face detection algorithm using Local Binary Pattern based features and Haar like features. The traditional and efficient Adaboost training scheme is adopted to train object features from publicly available databases. This work has been published in the ICVS Workshop [36] .

The work has been tested for group tracking in Vanaheim videos (see section 8.2.1.2 ) and for people tracking in VideoId videos. The VideoId project aims to re-identify people across a network of non overlapping cameras using iris, face and human appearance recognition. An example of tracked people, head and faces in a testing database is shown in figure 7 . An example of re-identified face is shown in figure 8 by the VideoId interface in a Paris underground video.

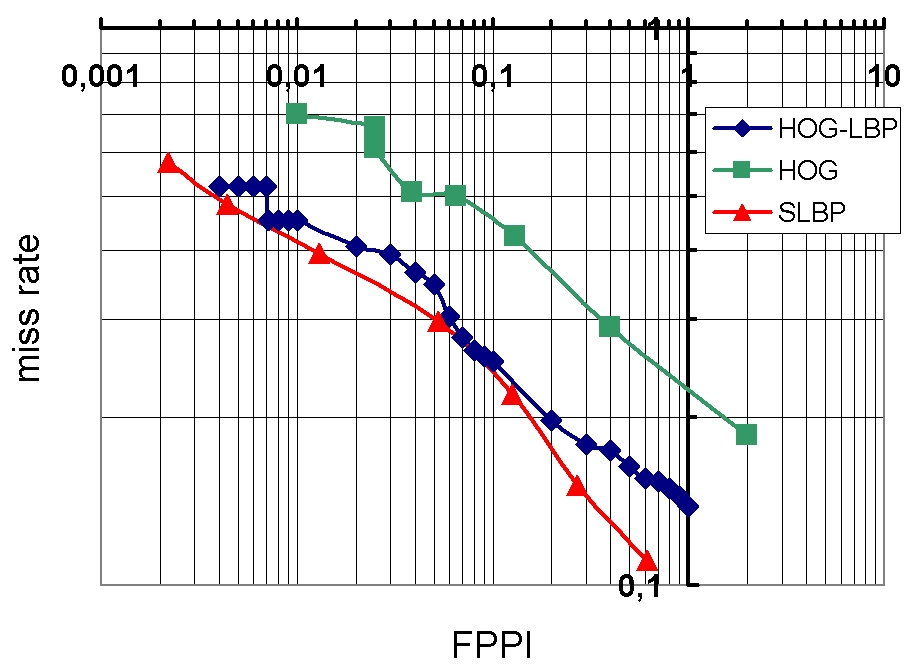
We have evaluated our people detection algorithm on the test human dataset provided by INRIA against state of the art algorithms which we refer as HOG [59] and LBP-HOG [77] . The INRIA human dataset is composed of 1132 human images and 453 images of background scenes containing no human. The results are displayed in figure 9 which shows that we obtain slightly better performances than the HOG-LBP technique in terms of missed detection rate vs. FPPI i.e. False Positive Per Image. In this figure, two extreme functioning modes could be chosen: approximately 2 noisy detections are obtained every 1000 background images for 50% true positive detections or 1 noisy detection every 2 frames for a detection rate of approximately 88%.
|
The same evaluation scheme of people detection above is used for face detection evaluation. The FPPI rates are obtained on 997 NICTA [66] background images of 720x576 pixels. 180 faces provided by a CMU test face image database are used to evaluate true positive rates. We have compared our results with the 2 versions of Haar feature provided by the OpenCv library i.e. the standard 'default' and alternative 'alt' training parameters. The results in table 1 show that the Haar 'alt' technique performs better than the traditional Haar one. And our haar based technique called CCR provides similar face detection rates while giving a less false alarm rate. The proposed approach is approximately 1% less successful in detecting faces than the Haar technique while this latter is 32% more noisier than our CCR technique.